AI News
Unraveling Multimodal Dynamics: Insights into Cross-Modal Information Flow in Large Language Models
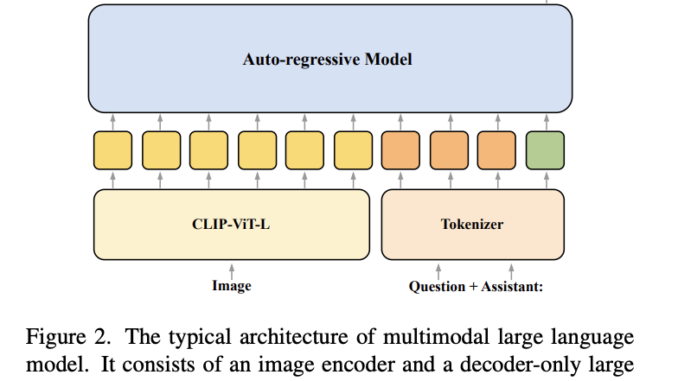
Multimodal large language models (MLLMs) showed impressive results in various vision-language tasks by combining advanced auto-regressive language models with visual encoders. These models generated responses using visual and text inputs, with visual features from an […]