
Generative AI models, driven by Large Language Models (LLMs) or diffusion techniques, are revolutionizing creative domains like art and entertainment. These models can generate diverse content, including texts, images, videos, and audio. However, refining the quality of outputs requires additional inference methods during deployment, such as Classifier-Free Guidance (CFG). While CFG improves fidelity to prompts, it presents two significant challenges: increased computational costs and reduced output diversity. This quality-diversity trade-off is a critical issue in generative AI. Focusing on quality tends to reduce diversity, while increasing diversity can lower quality, and balancing these aspects is crucial for creating AI systems.
Existing methods like Classifier-free guidance (CFG) have been widely applied to domains like image, video, and audio generation. However, its negative impact on diversity limits its usefulness in exploratory tasks. Another method, Knowledge distillation, has emerged as a powerful technique for training state-of-the-art models, with some researchers proposing offline methods to distill CFG-augmented models. The Quality-diversity trade-offs of different inference-time strategies like temperature sampling, top-k sampling, and nucleus sampling have been compared, with nucleus sampling performing best when quality is prioritized. Other related works, such as Model Merging for Pareto-Optimality and Music Generation, are also discussed in this paper.
Researchers from Google DeepMind have proposed a novel finetuning procedure called diversity-rewarded CFG distillation to address the limitations of classifier-free guidance (CFG) while preserving its strengths. This approach combines two training objectives: a distillation objective that encourages the model to follow CFG-augmented predictions and a reinforcement learning (RL) objective with a diversity reward to promote varied outputs for given prompts. Moreover, this method allows weight-based model merging strategies to control the quality-diversity trade-off at deployment time. It is also applied to the MusicLM text-to-music generative model, demonstrating superior performance in quality-diversity Pareto optimality compared to standard CFG.
The experiments were conducted to address three key questions:
The effectiveness of CFG distillation.
The impact of diversity rewards in reinforcement learning.
The potential of model merging for creating a steerable quality-diversity front.
The evaluations on quality assessment involve human raters to get acoustic quality, text adherence, and musicality on a 1-5 scale, using 100 prompts with three raters per prompt. Diversity is similarly evaluated, with raters comparing pairs of generations from 50 prompts. The evaluation metrics include the MuLan score for text adherence and the User Preference score based on pairwise preferences. The study incorporates human evaluations for quality, diversity, quality-diversity trade-offs, and qualitative analysis to provide a detailed assessment of the proposed method’s performance in music generation.
Human evaluations show that the CFG-distilled model performs comparably to the CFG-augmented base model in terms of quality, and both outperform the original base model. For diversity, the CFG-distilled model with diversity reward (β = 15) significantly outperforms both the CFG-augmented and CFG-distilled (β = 0) models. Qualitative analysis of generic prompts like “Rock song” confirms that CFG improves quality but reduces diversity, while the β = 15 model generates a wider range of rhythms with enhanced quality. For specific prompts like “Opera singer,” the quality-focused model (β = 0) produces conventional outputs, whereas the diverse model (β = 15) creates more unconventional and creative results. The merged model effectively balances these qualities, generating high-quality music.
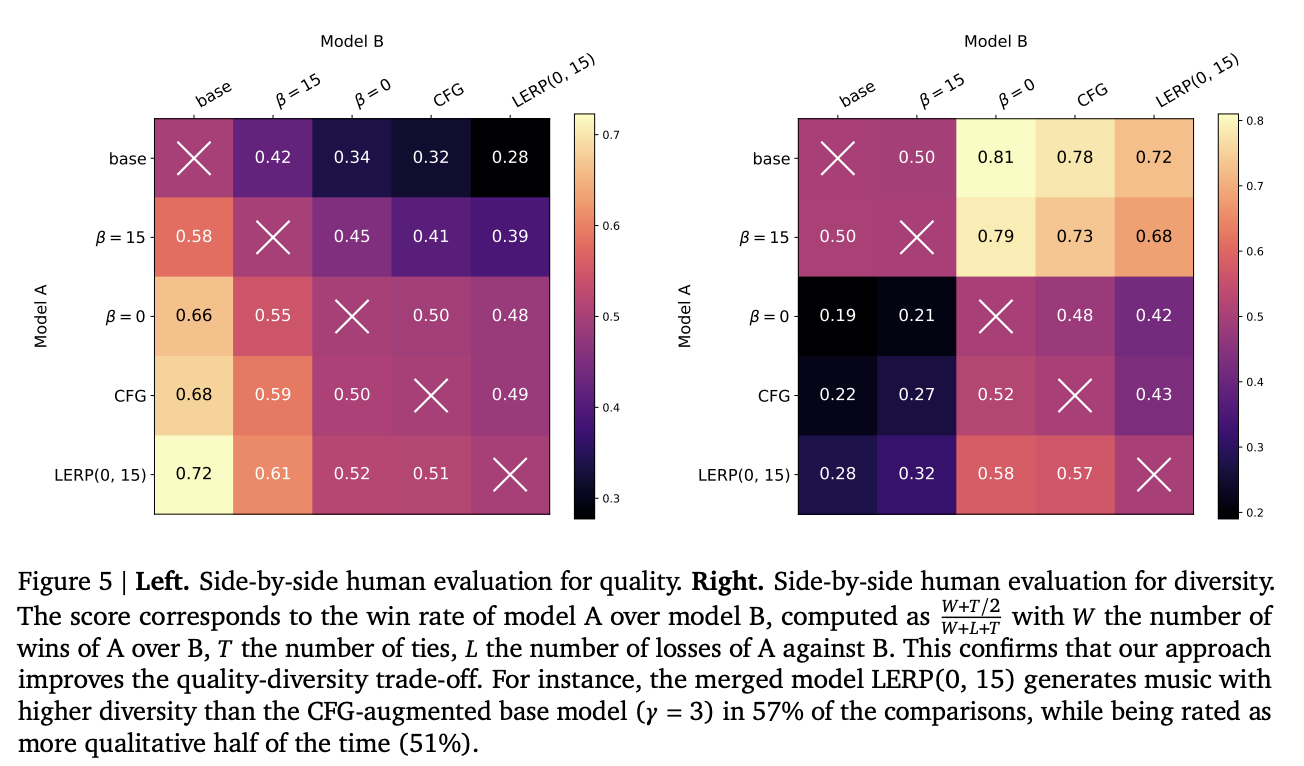
In conclusion, researchers from Google DeepMind have introduced a finetuning procedure called diversity-rewarded CFG distillation to improve the quality-diversity trade-off in generative models. This technique combines three key elements: (a) online distillation of classifier-free guidance (CFG) to eliminate computational overhead, (b) reinforcement learning with a diversity reward based on similarity embeddings, and (c) model merging for dynamic control of the quality-diversity balance during deployment. Extensive experiments in text-to-music generation validate the effectiveness of this strategy, with human evaluations confirming the superior performance of the finetuned-then-merged model. This approach holds great potential for applications where creativity and alignment with user intent are important.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
Be the first to comment