
The adversarial attacks and defenses for LLMs encompass a wide range of techniques and strategies. Manually crafted and automated red teaming methods expose vulnerabilities, while white box access reveals potential for prefilling attacks. Defense approaches include RLHF, DPO, prompt optimization, and adversarial training. Inference-time defenses and representation engineering show promise but face limitations. The control vector baseline enhances LLM resistance by manipulating model representations. These studies collectively establish a foundation for developing circuit-breaking techniques, aiming to improve AI system alignment and robustness against increasingly sophisticated adversarial threats.
Researchers from Gray Swan AI, Carnegie Mellon University, and the Center for AI Safety have developed a set of methods to enhance AI system safety and robustness. Refusal training aims to teach models to reject unsafe content but remain vulnerable to sophisticated attacks. Adversarial training improves resilience against specific threats but lacks generalization and incurs high computational costs. Inference-time defenses, such as perplexity filters, offer protection against non-adaptive attacks but struggle with real-time applications due to computational demands.
Representation control methods focus on monitoring and manipulating internal model representations, offering a more generalizable and efficient approach. Harmfulness Probes evaluate outputs by detecting harmful representations, significantly reducing attack success rates. The novel circuit breakers technique interrupts harmful output generation by controlling internal model processes, providing a proactive solution to safety concerns. These advanced methods address the limitations of traditional approaches, potentially leading to more robust and aligned AI systems capable of withstanding sophisticated adversarial attacks.
The circuit-breaking methodology enhances AI model safety through targeted interventions in the language model backbone. It involves precise parameter settings, focusing on specific layers for loss application. A dataset of harmful and harmless text-image pairs facilitates robustness evaluation. Activation analysis using forward passes and PCA extracts directions for controlling model outputs. At inference, these directions adjust layer outputs to prevent harmful content generation. Robustness evaluation employs safety prompts and categorizes results based on MM-SafetyBench scenarios. The approach extends to AI agents, demonstrating reduced harmful actions under attack. This comprehensive method represents a significant advancement in AI safety, addressing vulnerabilities across various applications.
Results demonstrate that circuit breakers, based on Representation Engineering, significantly enhance AI model safety and robustness against unseen adversarial attacks. Evaluation using 133 harmful text-image pairs from HarmBench and MM-SafetyBench reveals improved resilience while maintaining performance on benchmarks like MT-Bench and OpenLLM Leaderboard. Models with circuit breakers outperform baselines under PGD attacks, effectively mitigating harmful outputs without sacrificing utility. The approach shows generalizability and efficiency across text-only and multimodal models, withstanding various adversarial conditions. Performance on multimodal benchmarks like LLaVA-Wild and MMMU remains strong, showcasing the method’s versatility. Further investigation into performance under different attack types and robustness against harm category distribution shifts remains necessary.
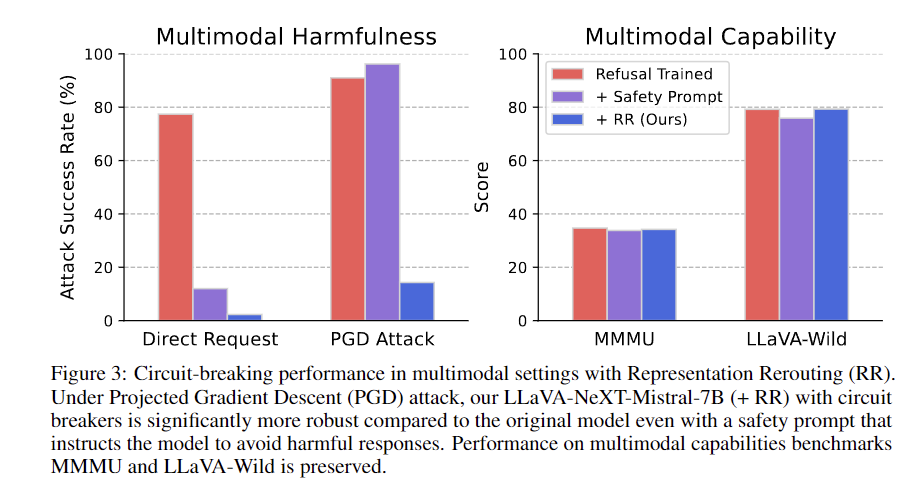
In conclusion, the circuit breaker approach effectively addresses adversarial attacks generating harmful content, enhancing model safety and alignment. This method significantly improves robustness against unseen attacks, reducing harmful request compliance by 87-90% across models. The technique demonstrates strong generalization capabilities and potential for application in multimodal systems. While promising, further research is required to explore additional design considerations and enhance robustness against diverse adversarial scenarios. The methodology represents a significant advancement in developing reliable safeguards against harmful AI behaviors, balancing safety with utility. This approach marks a crucial step towards creating more aligned and robust AI models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI
Be the first to comment