AI News
Salesforce AI Research Propose Programmatic VLM Evaluation (PROVE): A New Benchmarking Paradigm for Evaluating VLM Responses to Open-Ended Queries
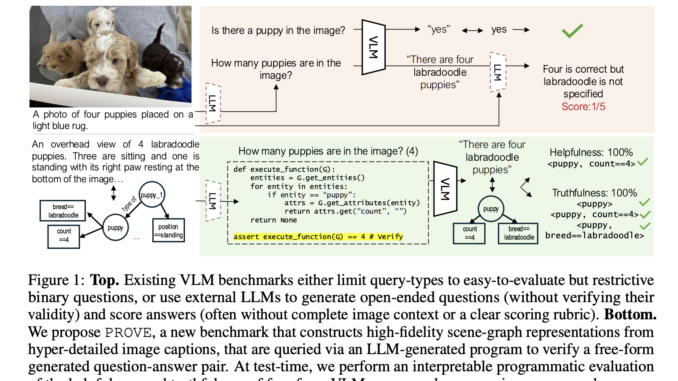
Vision-Language Models (VLMs) are increasingly used for generating responses to queries about visual content. Despite their progress, they often suffer from a major issue: generating plausible but incorrect responses, also known as hallucinations. These hallucinations […]